Ultimate AWS Certified Developer Associate 2019 - Part 3
Part 3 covers infrastructure as code using AWS CloudFormation, monitoring using CloudWatch, X-Ray and CloudTrail, and integrating applications using SQS, SNS and Kinesis.
AWS CloudFormation
Common Usage and Benefits
- declarative way to outline AWS infrastructure for almost all resources
- after declaring, AWS CF will automatically create resources in the right order
- users do not need to figure out the order of provisioning, and no need to worry about orchestration
- able to leverage existing CF templates on the web to deploy almost any stack
Control
- infrastructure created from code, no manual creation, less prone to human error.
- infrastructure as code can be version controlled
- changes to infrastructure can be reviewed from code
- infrastructure can be created and destroyed on the fly
- automated AWS resource diagram generation
- separation of concern by creating many different CF stacks for many apps and many layers e.g. a VPC stack, a network stack, an app stack
Cost
- each resource in a CF stack can be identified helps with cost estimation and calculation
- enable cost saving strategy, e.g. routinely create stack in the morning and delete stack at the end of day.
CF process
- templates are first uploaded to S3 and then referenced in CF
- we update templates by re-uploading a newer version to S3
- CF creates stack based on declaration in template
- stacks are identified by a name
- deleting a stack deletes every single artifact that was created by CF
CF Template Components
Mappings:
RegionMap:
us-east-1:
"dev": "us-east-1a"
"test": "us-east-1b"
"prod": "us-east-1c"
Resources:
MyInstance:
Type: AWS::EC2::Instance
Properties:
AvailabilityZone: !FindInMap [RegionMap, !Ref AWS::Region, !Ref Env]
InstanceType: !Ref InstanceTypeParam
SecurityGroups:
- !Ref ServerSecurityGroup
- !ImportValue SSHSecurityGroup
ServerSecurityGroup:
Type: AWS::EC2::SecurityGroup
Properties:
SecurityGroupIngress:
- IpProtocol: tcp
FromPort: 80
ToPort: 80
CidrIp: 0.0.0.0/0
Parameters:
InstanceTypeParam:
Type: String
Default: t2.micro
Env:
Type: String
Default: dev
Outputs:
InstanceID:
Condition: IsProdEnv
Value: MyInstance
Export:
Name: MyInstanceRefId # used by other stacks when importing
Conditions:
IsProdEnv: !Equals [ !Ref Env, prod ]
- Notes
- Dashes are used to indicate array elements in YAML
!Refis used to refer to parameters / resources!FindInMapis used to get value from Mappings!ImportValueis used to import value from the Output of other stacks- Intrinsic function used by Conditions are
Fn::And, Or, Equals, If, Not !GetAttis used to obtain attribute of a resource!Join [ delimiter, [list of values] ],!Sub [ target, { currentVal: newVal } ]are String manipulation functions.
- Resources (mandatory)
- represents the AWS components to be created / updated
- identifier of the form
AWS::aws-product-nam::data-type-name
- Parameters
- useful to dynamically provide inputs to CF templates
- especially if you want to reuse components
- or if values cannot be determined ahead of time
- can be controlled with various settings such as data type, constraints, min/max length and value, defaults, allowed values and patterns etc
- AWS provides pseudo parameters that can be used at anytime in the CF template, such as:
- AWS::AccountId
- AWS::Region
- AWS::StackId
- AWS::StackName
- Mappings
- Key-Value pairs that are used to declare values in bulk if you know the values ahead of time.
- Outputs
- declares values to be exported from CF stack
- these values can be used by other stacks
- some values can only be determined after stack is created, such as Subnet ID, or VPC ID, and Output is the dynamic way to obtain these values
- NOTE CF stack cannot be deleted if its output values are referenced by another stack
- Condition
- Logical evaluation to determine condition of deployment
- Can be applied to resources / outputs etc.
CF Rollbacks
- On Stack Creation Failure
- default is to rollback and delete all resources created by CF, and users will only be able to refer to the logs.
- disabling the default will stop rollback, allowing you to troubleshoot.
- On Stack Update Failure
- Stack automatically rollback to previous working state
- See the logs to find error messages
AWS CloudWatch
CloudWatch Metrics
CloudWatch provides Metrics for every service in AWS
- Metrics belong to namespaces
- Dimensions are attributes of a metric (up to 10)
- Dimensions can be used to segment metrics
- Metrics have timestamps
- Can be used to create dashboards
EC2 Metrics are collected every 5 minutes
- turn on detailed monitoring for 1 minute granularity
- will cost more, but also allow more prompt ASG scaling (free tier allows up to 10 detailed metrics)
- EC2 memory usage must be pushed from within EC2 instance as a custom metric
Custom Metric
- Standard resolution is 1 minute
- High resolution up to 1 second (using StorageResolution API parameter, for PutMetricData API). High cost.
- Exponential back off in case of throttling
CloudWatch Alarms
- Alarms are used to trigger notifications for any metrics
- Can notify Auto Scaling, EC2 Action, SNS Notification
- Various options (sampling, %, max, min …)
- Alarm States: OK, INSUFFICIENT_DATA, ALARM
- Period: length of time to evaluate metric (for high res custom metrics it is either 10s or 30s)
CloudWatch Logs
Apps can send logs to CloudWatch via SDK
- CloudWatch can collect logs from
- EB, ECS, Lambda
- VPC Flow Logs, API Gateway
- CloudTrail, CloudWatch log agents
- Route53
- CloudWatch Logs can go to
- Batch exporter for S3 archival
- Stream to ElasticSearch for analysis
Logging details
- can use filter expressions
- Logs are stored by
- Log Groups, usually representing an app
- Log Stream, representing instances of app
- Define log expiration policies (never, 30 days, etc)
- AWS CLI can be used to tail logs
- IAM permissions required to send logs to CloudWatch
- Encryption of logs using KMS at Log Group level
CloudWatch Events
Events can be generated in two ways
- Schedule, for running cron jobs
- Event Pattern, using event rules to react to state changes in various services
Events create small JSON document with details of the event.
Events can trigger Lambda functions, SQS/SNS/Kinesis Messages.
AWS X-Ray
X-Ray provides visual analysis of distributed services of your App in AWS
- troubleshoot performance, identify bottlenecks, throttles, impacted users
- mapping out dependencies in microservice architecture
- pinpoint service issues, review request behavior
- find errors and exceptions
- discover if SLA time is met
How X-Ray Works
X-Ray compatible services:
- Lambda, EB, ECS, EC2 instance or even on-premise App Servers
- ELB, API Gateway
How X-Ray works:
- trace end-to-end by following a requests
- each component a request passes through add its own trace to the requests
- trace is made up of segments (with sub-segments)
- annotations added to traces to provide extra information
- Able to trace every requests, or sample a percentage or rate of requests per minute
- IAM for authorization and KMS for encryption at rest
Two-Steps to enable X-Ray:
- App code must import AWS X-Ray SDK
- SDK will capture calls to AWS services,
- HTTP/HTTPS requests
- Database calls
- Queue calls
- Instance must run X-Ray daemon or enable X-Ray AWS Integration
- X-Ray daemon works as low level UDP packet interceptor (for EC2 instances)
- Lambda and other AWS services already has X-Ray daemon in place (called X-Ray integration)
- Each App must have IAM rights to write data to X-Ray
X-Ray Troubleshooting
Troubleshooting
- if X-Ray is not working on EC2
- ensure IAM role for EC2 has the required permissions
- ensure EC2 instance is running X-Ray daemon
- for Lambda
- ensure Lambda IAM execution role has require permission (AWSX-RayWriteOnlyAccess)
- ensure X-Ray is imported in the code
X-Ray additional exam tips
- X-Ray has configuration to send traces across account
- just need to assume role
- allows a central account for application tracing across multiple accounts
- Sampling will decrease the amount of requests sent to X-Ray, reducing cost
- each app / service will send segments
- segments collected for one request forms an end-to-end trace
- annotations are key-value pairs that will be indexed, so can be used to filter / search traces
- Turning on X-Ray for various services
- EC2 / On-Premise
- server instance must run X-Ray daemon
- appropriate IAM role for EC2, or AWS credentials loaded for on-premise server
- Lambda
- ticked X-Ray integration in lambda console
- IAM role with correct permissions
- Beanstalk
- set configuration in EB console
- Or, use EB extensions (.ebextensions/xray-daemon.config)
- ECS / EKS / Fargate (Docker)
- use Docker image that runs X-Ray daemon (or use official AWS X-Ray Docker image)
- ensure port mappings and network settings are correct
- ensure IAM roles are defined correctly
- EC2 / On-Premise
AWS CloudTrail
- for governance, compliance and audit for AWS account
- enabled by default
- history of events / API calls made with AWS account by
- console
- SDK
- CLI
- AWS Services
- can put CloudTrail logs into CloudWatch
- if resource is deleted, use CloudTrail to investigate
CloudTrail vs CloudWatch vs X-Ray
- CloudTrail
- audit API calls made by users / services / console
- detect unauthorized calls or root cause of changes
- CloudWatch
- metrics for app monitoring
- logs to store app logs
- alarms to send notifications in case of unexpected app metrics
- X-Ray
- automated trace analysis
- central service map visualization
- latency, errors, fault analysis
- request tracking across distributed system
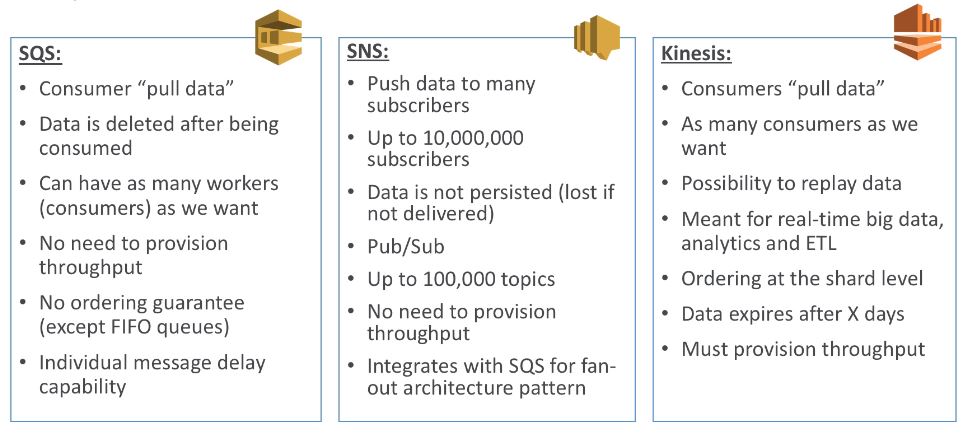
SQS
- oldest offering on AWS (10 years old)
- fully managed, scales from 1 to 10k messages per second
- message retention, 4 days (default) to 14 days
- no limit on number of messages
- low latency (less than 10ms on publish and receive)
- horizontal scaling for number of consumers
- may have message duplication occasionally (at least once delivery)
- can have out of order message (best effort ordering)
- 256 KB per message limitation
- VPC endpoint available
SQS Message Configs
- Message delay
- can set up to 15 minutes, between publish and available to consumer
- default is 0 seconds
- set at queue level
- each message can override default using DelaySeconds parameter
- Message visibility
- when message has been polled, it will be invisible to other consumers for a defined VisibilityTimeout
- set between 0s to 12h (default 30s)
- use ChangeMessageVisibility API to change visibility while processing the message
- Redrive Policy
- number of times the message will re-appear in the queue, if it fails to be processed by consumer during visibility timeout
- after threshold is exceeded, message goes into a Dead Letter Queue
- Long Polling
- blocking call by consumer to wait for messages to arrive
- decreases number of API calls made to SQS, which reduce costs but increase latency of consumer
- wait time between 1s to 20s
- can be set at queue level or at each request using WaitTimeSeconds API
Message Producer
- define message body
- add optional message attributes (key-value pairs)
- get back message identifier and MD5 hash of body as response
Message Consumer
- polls SQS for message (up to batch of 10 messages)
- process messages within visibility timeout
- delete message using message ID and receipt handle
SQS FIFO Queue
- new offering
- queue name must end in .fifo
- lower throughput (up to 3k per second with batching, 300 per second without)
- messages are processed in order
- messages sent exactly once
- no per message delay option (but can set delay at queue level)
Features
- De-duplication
- provide MessageDeduplicationId in message
- deduplication interval is 5 minutes, sliding window
- for content based deduplication, FIFO queue will generate MessageDeduplicationId using SHA-256 hash of message body (exclude message attributes)
- Sequencing
- FIFO queue only orders message within the same MessageGroupId
- messages across different group IDs can be received out of order
- to order messages for a user, use user ID as MessageGroupId
- each message group will only be delivered to one consumer
SQS Advanced Concepts
SQS Extended Client
- currently only for Java
- sends messages larger than 256 KB limit by first storing message in S3
- then sends S3 object metadata through SQS to consumer
- consumer retrieves full message from S3 using metadata
SQS Security
- encryption in flight using HTTPS endpoint
- can enable Server Side Encryption using KMS
- SSE only encrypts message body
- IAM policy required to use SQS
- SQS queue access policy
- fine grained access control over IP
- control time window of incoming requests
SQS APIs
- CreateQueue, DeleteQueue
- PurgeQueue, to delete all messages
- SendMessage, ReceiveMessage, DeleteMessage
- ChangeMessageVisibility
- Batch APIs variant of the above
AWS SNS
- Publish-Subscribe Pattern
- up to 10 million subscriptions per topic
- 100k topic limit
- possible subscribers
- SQS
- HTTP/HTTPS endpoints (with delivery retries)
- Lambda
- Emails, SMS messages, Mobile Notifications
Publish Message
- Topic Publish (for server SDK)
- create topic
- create subscriptions to topic
- publish to topic
- Direct Publish (for mobile apps SDK)
- create a platform application
- create platform endpoint
- publish to platform endpoint
- works with Google GCM, Apple APNS, Amazon ADM
SNS + SQS: Fan Out Pattern
- push once, received by many queues
- fully decoupled
- no data loss
- SQS adds features like delayed processing and retries to the pattern
- scale consumers of each queue independently
AWS Kinesis
- managed alternative to Apache Kafka
- Great for application logs, metrics, IoT, clickstreams, real-time big data
- Great for stream processing framework (Spark, NiFi)
- Data automatically replicated to 3 AZs
Three sub-products:
- Kinesis Streams low latency streaming ingest at scale
- Kinesis Analytics real-time analytics on streams using SQL
- Kinesis Firehose load streams into S3, Redshift, ElasticSearch
Kinesis Streams
- Streams are divided into ordered Shards / Partitions
- 1 MB/s or 1000 messages/s at write per shard
- 2 MB/s at read per shard
- billed per shard
- shards can be merged / reshard
- records are ordered per shard
- batching or per message calls
- data retention between 1 day (default) to 7 days
- multiple application can consume the same stream
- real-time processing with scale of throughput
- data inserted is immutable
Kinesis PutRecord API
- specify partition key to be hashed
- records with same key will be place in same partition
- messages gets a sequence number
- recommended to choose partition key that is highly distributed (prevent “hot partition” problem)
- put records in batch to reduce cost and increase throughput
- ProvisionedThroughputExceeded exception if usage goes over limit
- API can be used from CLI, SDK, libraries from various frameworks
ProvisionedThroughputExceeded Exceptions
- occurs when data write rate to shard exceeds limit
- recommended to avoid hot shard / hot partition
- if exception occurs, try
- retries with backoff
- increase shards (scaling)
- use a better partition key
Kinesis Client Library (KCL)
- KCL is a Java library that reads from kinesis stream
- Each Shard can only be read by one KCL instance
- so that records in each shard can be read in order
- Read progress is checkpointed into DynamoDB (requires appropriate IAM permissions)
- KCL can run on EC2, Elastic Beanstalk, on Premise Application
Kinesis Security
- IAM policies to control access / authorization
- encryption in flight using HTTPS endpoints
- encryption at rest using KMS
- encrypt / decrypt on client side
- VPC endpoints available
Kinesis Data Analytics
- perform real-time analytics on kinesis stream records
- auto scale
- managed
- billed for consumption rate
- real-time queries can create new streams
Kinesis Firehose
- fully managed service
- near real-time (60s latency)
- auto scale
- support many data format (pay for conversion)
- also billed for amount of data transferred
SQS vs SNS vs Kinesis