
Modern Software Architecture: Domain Models, CQRS, and Event Sourcing
Using Domain Driven Design (DDD) as the main approach perform Domain Analysis on the real world problems, we may choose from three software architectures to support our implementation: Domain Models, Command Query Responsibility Separation (CQRS), and Event Sourcing.
Modern Software Architecture Domain Models, CQRS, and Event Sourcing - Dino Esposito, accessed on PluralSight 2019
This course is a great introduction to the state of modern software design. The course seems to suggests that our usual practice of writing database-centric software is the root cause of our applications eventually growing into unmaintainable monstrosities.
Course Overview
The course covers 3 topics.
- Repositioning Domain Driven Design (DDD) as the ideal methodology to conduct domain analysis.
- Explore architectures supporting DDD that are implemented in software systems (Domain Model Pattern, CQRS, Event Sourcing)
- UX-first approach to designing software system.
For extra reading, Esposito recommends following this project https://github.com/mastreeno/Merp which is an open source ERP system built using DDD and CQRS architecture.
Domain Driven Design Overview
when building software, there are always 2 choices - just building something vs building something right. Although the end result may appear the same to the end users, the working software may have been built using a wrong approach, which may turn into a technical debt that you are going to pay at some point.
DDD is a software design approach introduced by Eric Evans over a decade ago. Primary intent was to tackle complexity in the heart of software.
You can think about the complexity of software as the same complexity in the real world. Developers are merely describing what they can see in the real world problem with programming languages.
Without DDD, a typical software development project may look like this:
- gather requirements
- build a (relational) data model
- identify tasks the system has to do with the data. (sequence of tasks forms the so-called business logic)
- build UI for those tasks.
- produced artifacts close to meeting user needs to fails acceptance tests.
- repeats process to refine artifact.
Developers lack domain knowledge and this makes the software development an unmanageable process if the complexity passes certain threshold.
Big Ball of Mud (BBM)
A system that’s largely unstructured, padded with hidden dependencies between parts, with a lot of data and code duplication and an unclear identification of layers and concerns - a spaghetti code jungle.
DDD has been the first attempt in the industry to organize and systematize a set of principles and practices to build sophisticated software systems reliably and more easily.
DDD was like the traditional approach, which is still aimed at organizing business logic. However, it focuses more on a domain, which is both data and behavior, instead of just data.
Here is what a DDD flow may look like:
- crunch as much knowledge about the domain as possible, to capture all internal dynamics and how things work in that domain in the real world. May seek the help of domain experts, but that is not sufficient to form specifications and requirements.
- split the big domain into multiple subdomains
- design a rich object model for each recognized subdomains. Design regardless of concerns like persistence and databases first, focus on describing how entities behave and what are the user actions.
- code by telling objects in the domain model what to do.
Dream of every developer is to build an all-encompassing object model describing the entire domain.

In 2009, DDD shifted focus. It became a tool used for discovering domain architecture more than organizing business logic. Domain Model Pattern remains a valid pattern to organize business logic bit other patterns can be used as well:
- Object-oriented models
- Functional models
- CQRS
- Classic 3-tier
- client/server 2-tier More info in youtube video: Eric Evans talk at QCON 2009
DDD Misconceptions:
- it is about building object model for the business domain and calling it “domain model”
- consume the domain model in a multi-layer architecture (with app layer, domain layer, etc.)
But in actual fact the most valuable part of DDD is the tools it provides to help us make sense of a domain. This enables you to Design the system, Driven by your knowledge of the Domain.
DDD actually has 2 distinct parts.
- the Analytical component:
- sets the top level architecture for the business domain
- this top level architecture is expressed as constituent elements subdomains that are called Bounded Contexts.
- the Strategic component:
- relates to the definition of supporting architecture for each of the identified Bounded Contexts.
The Analytical component is valuable to everyone. However, the Strategic component, which uses Domain Model Pattern and multi-layered software architecture, is just one of several possible supporting architectures and it is not necessary for every project to use the Strategic component when practicing DDD.
Domain Analysis
Three main tools:
- Ubiquitous Language
- Bounded Context
- Context Map
Ubiquitous Language
A business oriented language to help the entire development team unify their mental model of the domain. It should be:
- Vocabulary of domain-specific terms, such as nouns, verbs, adjectives, idiomatic expressions and even adverbs
- Shared by all parties involved in the project, to avoid misunderstandings.
- Used in all forms of spoken and written communication, adopted as the universal language of the business conducted in the organization.
- Natural language not artificial language, so that it uses most of the business terminology.
- Derived from interviews and brainstorming
- Iteratively composed, the language can be refined as the development progresses.
- Unambiguous, rigorous, and fluent, to meet the expectations of both domain experts and technical experts.
Using the language in all forms of communication includes but not limited to:
- User Stories & RFC
- Meetings & Emails
- Technical Documentation & Source Code
A glossary of terms is an artifact of the language, made available to everyone as part of the project documentation and should be actively updated and maintained by the development team.
How to get started?
- Start from user stories, identify all the keywords related to the domain, such as nouns and verbs.
- Next form the glossary of terms and use them consistently across the project.
- Hold meetings for domain and technical experts to agree on using consistent language expressions to avoid ambiguity. For example, “delete an order” is a technical expression while “cancel an order” is a business expression, but since both expressions refer to the same action in the domain, the team should standardize to use a single expression.
- Iteratively refine the glossary of terms to better reflect the domain.
- The source code and technical documents should be updated regularly and be in-sync with changes in the glossary of terms.
Additional Tips
- Hiring developers with domain expertise may not add as much value as you would expect, since there are no two identical domains in the world. Every business has a unique internal dynamics.
- A word-to-word translation map of the glossary of terms may be required for an international team.
- Ubiquitous Language excels in a business environment with a lot of domain logic, and also in a start up environment which the company itself is still discovering and refining their own business domain along the way.
Here is how Ubiquitous Language can be applied to the source code. Note that once the software fails to capture a domain-specific point, it will likely results in a bug.
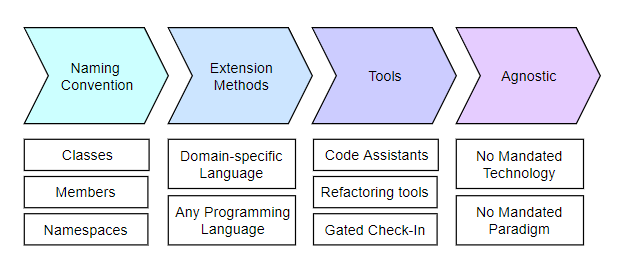
Bounded Context
Ubiquitous Language, though powerful, cannot be extended indefinitely to encompass the entire universe without growing too cumbersome to be used and maintained. Another tool is required to set boundaries and limit the Ubiquitous Language to a specific context.
Bounded Context is a tool that provides:
- Delimited space where an element has a well-defined meaning, as defined by the corresponding Ubiquitous Language.
- Boundaries to the context, and each context has its own Ubiquitous Language. Beyond the boundaries, the language changes and terms no longer carry the same meaning.
- Splitting of business domain into a web of interconnected contexts, each context has its own architecture and implementation.
Through the use of Bounded Contexts, we remove ambiguity and duplication in the software. Breaking down the domain into contexts simplify design of software modules, and provides an approach to integrating external components. Here is how we may visualize the problem and solution space:

Every Bounded Context has 3 components:
- its own set of Ubiquitous Language.
- its own independent implementation (e.g. CQRS).
- external interface to other contexts/systems.
In the traditional software design approach, any attempt to create a single, all-encompassing, flexible software model will run into the following risks of breaking the model integrity:
- Same term has different meanings to different people
- Same term has been used to indicate different elements
- Dependency on external subsystems
- Dependency on legacy code
- Functional areas of application are better treated separately
Defining Bounded Context is not a trivial process, and often this process needs to consider Context Mappings.
Context Mapping
Bounded Contexts often reflects the actual physical organization within a business. For example, a Finance department can be modelled in a Finance Bounded Context, and even though Finance works closely with the Procurement department, Procurement will be modelled in a separate context.
A Context Map is a diagram that provides a comprehensive view of the system being designed by indicating the relationships between all the Bounded Contexts that form the business domain.
List of Context Mapping Relationships
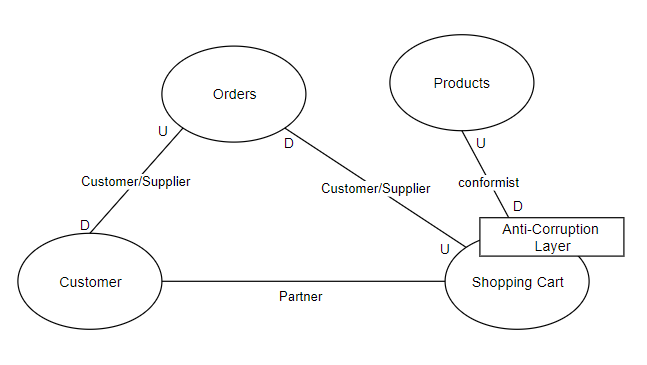
- Conformist: downstream context depends on upstream context, not negotiable to make changes. Typically used when working with external or legacy systems.
- Customer/Supplier: downstream context depends on upstream context, but is able to negotiate with upstream team to make some changes.
- Partner: contexts that mutually depends on each other.
- Shared Kernel: a piece of model is shared by two contexts. Changes cannot be made to the model without seeking approvals from both teams.
- Anti-Corruption Layer: extra layer in front of the downstream context to ensure that the downstream context see a fixed interface, regardless of what happens to the upstream context.
DDD Practice: Event Storming
Similar to brainstorming exercises that help teams to generate ideas, Event Storming guides domain and technical experts to explore the business domain and generate observable domain events.
How to get started?
- Gather the team. Ideally a two-pizza team size.
- Prepare post-it notes, whiteboards and markers.
- Identify relevant domain Events, write them down on notes and pin on the wall.
- Identify all the causes of an Event:
- write the relevant User Actions down on a note
- write any relevant Asynchronous Event down on a note
- write any other relevant Events down on a note
- pin all of them near the initial domain Event.
- (the different types of notes should be color-coded)
- The wall of notes forms a timeline of events. Use markers to make annotations.
- (Optional). You may engage a facilitator to guide the discussions and keep everyone on track. The facilitator does not need any domain knowledge.
The following diagram describes the outcome of a fruitful Event Storming exercise:
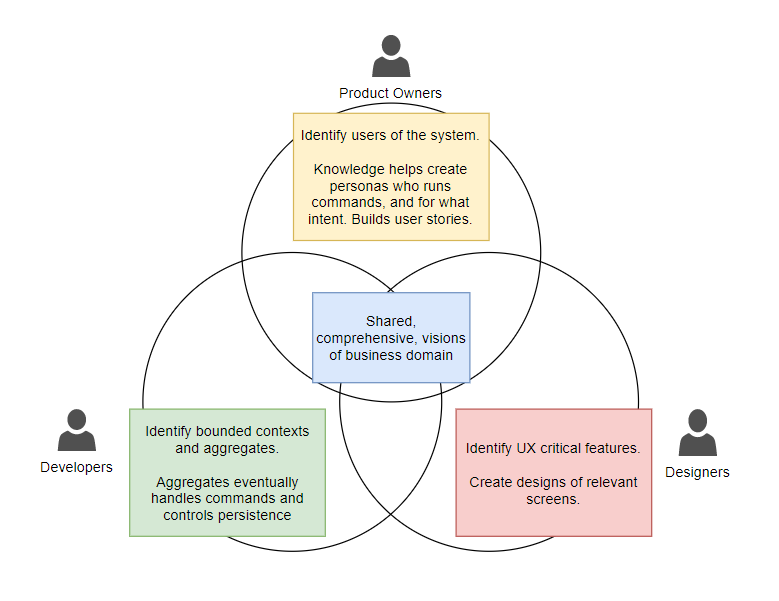
Aggregate refers to software components that handle commands and events, and also controls persistence. Persona refers to a written representation of a specific user which can be used to make decisions about software features.
Interesting article about Story Mapping, quite similar to Event Storming: https://blog.eriksen.com.br/en/mapping-domain-knowledge
A talk about how Event Storming has evolved over time: https://youtu.be/1i6QYvYhlYQ
Layered Architecture
Just to clarify the terms, a Layer refers to a logical container for a portion of code, while a Tier refers to a physical container or process space in which the code is deployed.
The classic “3-Tier” architecture, by the strict terminology, is actually 3 layers (Presentation, Business, Data), deployed across 2 tiers (web server, database server)
DDD layered architecture is a variation of the classic architecture which attempts to enforce separation of concerns by containing the business logic within the Application and Domain layers without leaking to the other layers.
- Presentation Layer: same as classic presentation layer.
- Application Layer: bridges model and services with the presentation layer.
- Domain Layer: contains model and services.
- Infrastructure Layer: includes data layer, any concrete technologies, and cross-cutting concerns. (For example, security, logging, caching, dependency injection).
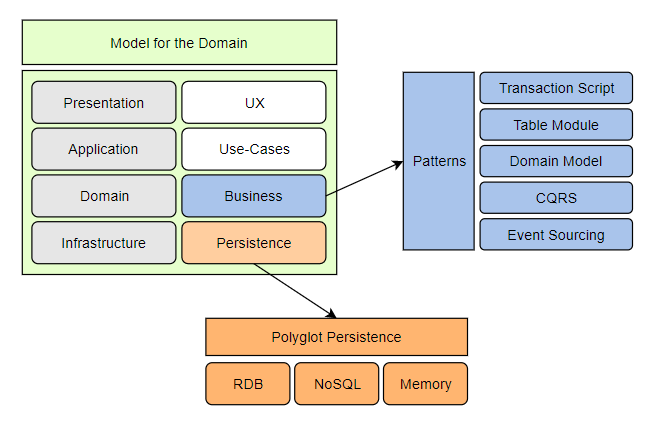
Each layer maps nicely to an area of architecture concerns, and we can select the appropriate design pattern to resolve each of the architecture concerns separately.
Presentation Layer
This layer is provides user interface to accomplish tasks in the system. User commands entered from this layer is relayed to the Application layer and then routed through the various layers.
Presentation can be seen as a collection of screen displaying data coming from the Application (View Model) and sending data back to the Application (Input Model).
Presentation layer has 2 key responsibilities:
- provide user interface to accomplish any required tasks.
- provide effective, smooth and pleasant user experience.
A good Presentation layer has the following attributes:
- task-based
- device-friendly
- user-friendly
- faithful to real-world processes
Application Layer
This layer separates Presentation from Domain and is where the software orchestrate the implementation of use-cases.
Application layer has 2 key responsibilities:
- reports to the Presentation: serves ready-to-use data in required format
- orchestrates tasks triggered by Presentation: satisfying use-cases of the application’s frontend
As such, the Application layer is doubly-linked with Presentation layer, and will need to be extended or duplicated when a new frontend is added. To ensure a good user experience, the link between the two layers should be established right when the user interface is designed.
Business Logic
The abstract definition of Business Logic in DDD is made up of 2 parts:
- Application Logic: which are dependent on user-cases, contains Data Transfer Objects (containers of data flowing to and from Presentation) and Application Services (orchestrate tasks and workflows).
- Domain Logic: Invariant to use-cases, contains Domain Model (holds data and behavior) and Domain Services.
Domain Logic is all about embedding business rules into code. Business rules are statements that detail the implementation of a business process or describe a business policy to be taken into account. A few patterns are available for organizing business logic:
- Transaction Script Pattern: this is a procedural approach. Each user action from the Presentation layer triggers an Application layer endpoint, that invokes a script. The script will see the entire logical transaction end-to-end.
- Table Module Pattern: this is a database-centric approach. One module is created per table in the database and contains all the queries and commands to interact with that particular table. The Application layer will need to determine which module to call for different steps of a workflow.
- Domain Model Pattern: is an object-oriented model that fully represents the behavior and processes of the business domain. Classes represents live entities in the domain, and contain properties and methods reflecting actual behavior of these entities and associated business rules. Aggregate Model refers to the core object of a domain model. These classes are persistence agnostic, and access domain services to interact with persistence layer.
Important Note 1: The term “Domain Model Pattern” may lead to some confusion.
Here we are referring to a pattern proposed by Martin Fowler, and this is not strictly part of the DDD theory. The term “Domain Model” used by Eric Evans is a generic term that simply means modelling software components according to business domain. When DDD was first introduced, many adopted the
Important Note 2: Just to summarize and reiterate the concepts and Application and Domain logic.
The Application logic deals with data coming from user interface, and handles it to ensure that use-cases are satisfied. (Important! use-cases are defined as what you can do on the user interface, and the outcome it produce).
The Domain logic however represents invariant properties of business that must still work regardless of use-cases. For example, if we are modelling a financial accounting system, then the important accounting rules should still holds in the system regardless of user interface and use-cases, and such rules belongs to Domain logic.
Domain Layer
This layer holds the essential logic of the business, invariant to user-cases. It consists of:
- Domain Models (not necessarily domain model pattern)
- Domain Services (handles persistence)
Domain Models
Can be created as object-oriented entity model or functional model. Object-oriented model should follow DDD conventions (using factories instead of constructors, using value types over primitive types, avoid private setters, expose both data and behavior).
Anemic Domain Models
Implementing the domain models using an anti-pattern. Objects are plain data containers instead, and all behavior and rules are moved to domain services.
Domain Services
The broader definition is pieces of domain logic that do not fit into any of the existing entities. There are only two scenarios:
- Behaviors that span multiple domain entities and hence cannot be fit into any domain models.
- Implementation that requires access to persistence layer or external services.
Infrastructure Layers
Fundamental facilities and services required for software to operate. Includes:
- Persistence
- Security
- Logging and Tracing
- Inversion of Control
- Caching
- Networks
This layer holds concrete details of technologies, such as connection strings, file paths, TCP addresses, and HTTP URLs, but it should not bind the system to any specific products. This means that technology details should be hidden from view, and can be easily replaced with other equivalent technologies.
Supporting Architecture: Domain Model Pattern
In this pattern, we will focus on the Domain Model, which implemented using object-oriented model, and Domain Services which deal with cross entity logic and data access. We can imagine this layer as an API to the business domain, and we should make sure that wrong calls to the API do not break the integrity of the business. Therefore, it is all about mapping the correct behavior from business into software.
To address some misconceptions up front:
- this pattern is not a simple and typical object model with some special characteristics, even though we are using object model for the purpose of this course. Context mapping is paramount, and as long as good principles are followed, we can implement domain model even with functional models or anemic models.
- database is not merely part of the infrastructure which can be neglected. Although the focus on the object model is to capture the business domain, it must still be easy to persist as we must eventually store the data somewhere.
- ubiquitous language is not just a guide to naming classes in the object model. As stated earlier, it is a unified understanding of the business.
Domain Model
Domain models are essentially the logical organization of entities and values in the domain.
Modules are like namespace in the code. Entities and values are grouped into modules.
Value Objects are fully identified by a collection of attributes. The attributes are never changed once the instance of the object has been created. Therefore:
- value types are a collection of individual values.
- and they are immutable.
- and they can more precisely and accurately represent business quantities than primitive types but to the custom definition we have given to them.
Entities also have a collection of attributes, but it must have an identifier. Therefore:
- uniqueness of the object is important for the business.
- it consists of data and behavior.
- but does not contain persistence logic.
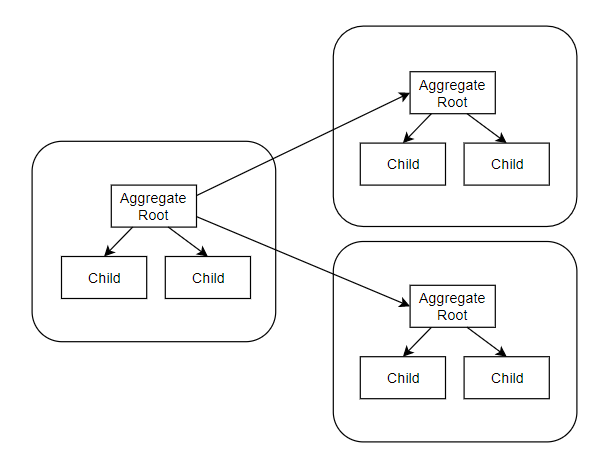
Aggregates are a few individual entities constantly used and referenced together.
- they are a cluster of associated objects, including their relationships, treated as “one entity” for making data changes or queries.
- the cluster has a root object called Aggregate Root which is the public endpoint. Access to members of the aggregate is always mediated by the root.
- Aggregates are separated by a consistency boundary. Design of aggregates are inspired by business transactions. An aggregate preserves the transactional integrity and ensures consistency of the business process it is trying to render.
Persistence Model vs Domain Model
Persistence Model is what we are familiar with, the data model in traditional object-oriented software design. The model closely reflects the underlying data storage (think ORM) and does not include business logic except for simple data fields validation.
A Domain Model focus on business logic, with no awareness of how data are stored in underlying persistence.
So this is ultimately a decision between maintaining objects as pure data containers and having the logic in some other services, or storing business logic directly within objects.
What is Behavior?
- Methods that validate the state of the object
- Methods that invoke business actions to perform on the object
- Methods that express business processes involving the object
The fundamental problem of not baking behavior into objects and having public getters and setters that can directly modify objects as pure data containers, is that there is no guarantee that the consumer of the domain model will maintain the integrity data and consistency with the business domain. For example, the setting a data object defined as Int32 to a negative value is consistent and valid according to the technical implementation, but this negative value may not make business sense if it was supposed to be representing the age of the user.
Here is an example of data-centric object model design:
// Person.java
public class Person {
public Person() {};
private Age ageObj;
private String name;
// Getters
public Age getAge() {
return age;
}
public String getName() {
return name;
}
// Setters
public void setAge(Age ageObj) {
this.ageObj = ageObj;
}
public void setName(String name) {
this.name = name;
}
}
// Age.java
public class Age {
public Age() {};
private Integer currentAge;
public Integer getAge() {
return currentAge;
}
public void setAge(Integer age) {
this.currentAge = age;
}
}
Re-writing the above using a domain model approach, we have the following:
// Person.java
public class Person {
private Age ageObj;
private String name;
public Person(String name) {
this.name = name;
this.ageObj = new Age();
};
// Informational
public Age getAge() {
return new Age(ageObj); // returns a copy of age
}
public String getName() {
return name;
}
public Boolean setAge(Integer age) { // behavior of object is constrained by logic
if (Age.aboveMinimum(age)) {
this.ageObj = new Age(age);
return true;
}
return false;
}
// Behavior
public void incrementAge() { // this logic would have been separately implemented by API caller
this.ageObj = new Age(ageObj.getAge + 1);
}
}
// Age.java
public class Age {
private Integer currentAge;
public Age(Integer age) {
this.currentAge = age;
}
public Age() {
Age(0);
}
public Age(Age ageObj) {
Age(ageObj.getAge());
}
public Integer getAge() {
return currentAge;
}
public static Boolean aboveMinimum(Integer age) {
return age >= 0; // business logic baked into object
}
}
// was a bit lazy and used implicit type conversion from primitive to generics
Aggregates and Value Types
Aggregates protect as much as possible the graph of entities from outsider access. The aggregate root ensures:
- the state of child entities is always consistent,
- takes care of persistance for all child entities,
- cascade updates and deletions,
- and ensures that access to child entities always happen by navigation from root only.
- (Each aggregate root has one dedicated repository service that implements consistent persistence for all of the objects).
The actual boundaries of aggregates are determined by business rule and also what the architect envision of the domain.
In the actual code, aggregates need not be created as features, but may be set as interfaces or abstract classes, implemented by entity classes.
Factory methods has an advantage over constructors. The factory method names are self-documenting, and give a purpose to the creation of objects at the point of invocation.
Domain Services
Even though Domain Services include logic that spans multiple aggregates and consume persistence or external service, it is not just a simple helper classes.
Domain Services comes from requirements approved by domain experts and are strictly part of the ubiquitous language.
Repositories are classes that handles persistence on behalf of entities that are ideally aggregate roots. It is the most popular type of domain service, has a direct dependency on the data stores and is where we actually deal with connection strings and SQL commands and etc.
Domain Events
Use of events is an increasingly popular way to express the interactions in real-world business domains, that proved to be more effective and resilient. But it is not strictly necessary.
If the business logic needs to be triggered sequentially, implementing those tasks in a single function or series of function calls will explicitly writes the sequence into code, which will lead to a monolithic structure that is difficult to maintain in future. By having a preceding function emit an event instead, this event can be received and acted on by multiple listeners. The event bus can be handled by underlying infrastructure and the event logic is agnostic to the concrete technology.
Anemic Models
Using Code First approach with Entity Framework (or making any ORM the central approach to your software design) inevitably leads to:
- a persistence model as the classes cannot fully represent the domain.
- adding behavior to the model to express the ubiquitous language may not always be possible, and if compromise have to be made, the ORM will always triumph.
- database being the constraint of the domain model.
Domain driven design can be adopted on a gray scale. People have widely adopted the anemic model alongside other good DDD practices. This may be due to legacy, habit, or simply their environment, and the resulting software has worked well for them. However, Martin Fowler has commented that these developers are robbing themselves of the true benefit of a domain model.
Supporting Architecture: CQRS
Command Query Responsibility Segregation emerged as a new alternative to object-oriented approach of representing the business domain, the latter which has proven over the years to be inadequate in capturing all the domain complexities and intricacies. CQRS is essentially about separating commands and queries using distinct application stacks.
Looking back at the two implementation to the domain layer,
- using Domain Model Pattern / Behavior-Rich Classes is great for commands that mutates the state of the system. However, it will require fixes to fully support persistence via ORM to read data, and it may expose unnecessary behavior to the presentation layer.
- using Anemic Model / Database-Centric Approach is great for queries that simple needs to read data from the system. However, the danger of such interface with no business rules means that the system may potentially end up in an incongruent state.
(Command alters state but doesn’t return data. Query returns data but doesn’t alter state.)
Since it is difficult to have one single implementation, CQRS emerged as an alternative to make the responsibilities distinct and each have its own implementation.
The benefits of CQRS are the possibility of distinct optimization and higher scalability potential, simplified design and hassle-free stacks enhancement.
Here is a comparison between the layered architecture and CQRS:

CQRS Basic: Single Database
To implement the most basic CQRS for a CRUD use case, the course suggested:
- for Command stack use any pattern that fits better.
- for Query stack use any code that does the job.
You may even use existing technologies and skills, just need to have a separation between Command and Query.
If this CRUD feature is implemented for a REST API, then Commands should respond with a POST-REDIRECT-GET pattern to redirect the user client to make a Query. This ensures that when user attempts to perform browser refresh to repeat the last action, it is always a Query, not a Command.
Example pseudo code below:
public class APIController implements Controller{
private ServiceInterface _crudService;
public APIController(ServiceInterface service) {
this._crudService = service;
}
@GET
public APIResult readRecord() {
OutputModel model = _crudService.get();
return new APIResult(model);
}
@POST
public APIResult createRecord(InputModel model) {
_crudService.write(model);
return redirectToGetRequest();
}
}
public class CrudService implements ServiceInterface {
private DbContext readOnlyContext;
private DbContext fullContext;
public OutputModel get() {
return readOnlyContext.query(); // uses a read-only context
}
public void write(InputModel model) {
fullContext.add(model); // uses a full-access context
fullContext.commit();
}
}
CQRS Intermediate: Two Databases
Now for a more sophisticated implementation, the underlying storage technology used by Command and Query may be different, and each may be optimized independently.
- Command stack can be optimized to be more task-oriented, focused on processing with no regards for data model, and even use ad-hoc storage technologies.
- Query stack may use any ORM or any database query expression library, but the underlying storage should still be relational database for the best query performance in most cases.
The problem facing such design is the stale data residing on the Query stack. There are a number of ways to keep data in sync between the two stacks.

Example pseudo code using the simplest synchronous strategy below:
public class APIController implements Controller{
private CommandService _cmdService;
private QueryService _qryService;
public APIController(CommandService service) {
this._cmdService = service;
}
@GET
public APIResult readRecord(String id) {
OutputModel model = _qryService.get(id);
return new APIResult(model);
}
@POST
public APIResult runTask(String id, EventType type) {
_cmdService.processAction(id, type);
return redirectToGetRequest(id);
}
}
public class CommandService {
public void processAction(String id, EventType type) {
switch (type) {
case EventType.CREATE:
EventManager.log(id, type, new Datetime());
break;
case EventType.RUN:
EventManager.log(id, type, new Datetime());
break;
case EventType.UNDO:
EventManager.remove(id);
break;
}
}
}
public class EventManager {
private static EventStore db = new EventStore();
public static void log(String id, EventType type, Datetime time) {
EventObj event = EventBuilder.build(id, type, time);
db.write(event);
db.commit();
OutputModel model = db.read(id); // immediately synchronize with Query stack
QueryViewStore.save(model);
}
}
CQRS Advanced: Event Source
The more sophisticated implementations use message-based communication.
Message can either be a Command or an Event. It typically has a base class to specify essential attributes such as:
- Date Time Stamp
- An Identifier
Then each Command or Event may extend the base class and include more details to describe the command or the event.
User actions, asynchronous streams, or receiving other events may cause the Application layer to send a new message to the Command stack. Therefore, this task-oriented approach mirrors business processes closely and allows new events and actions to weave in and out of the existing system easily.
- Command stack has a shared message bus that allows Application layer to push new Commands or Events to the other components listening to the bus that need to respond to these messages.
- A long running process that may need to act on a sequence of Commands/Events before it terminates is called a Saga.
- A short-lived executor that start-up and shutdown just to act on a Command/Events is called a Handler
- Both Sagas and Handlers may be implemented by Domain Models and Domain Services (mentioned in previous chapter) to reflect the business domain. The Domain Services will help to persist the updated system state in storage.
- (if the messages in the bus is persisted in a storage, the storage can act as an event store, and that forms the basis of Event Sourcing)
- Query stack can be implemented with any technology, but relational database as the underlying storage will likely give the best performance. It can even be implemented as a Handler, listening to the same message bus.
More on Sagas
- Sagas need to have unique identifier.
- The bus will only keep track of the list of listening Sagas and Handlers and dispatch messages to them. (this makes the bus a fairly dumb and simple mechanism)
- Within the Saga, it handles the business process triggered by the Command or Event.
- Within the Saga, it also lists all the Commands/Events that it can handle or is interested in.
- Sagas may require persistence of the incoming messages, and this is typically handled by the bus.
- Sagas may either be state-ful or stateless.
- New features can be added to the system simply by writing a new Saga/Handler and registering it with the bus.
Supporting Architecture: Event Sourcing
Events are what we actually observe in the real world, but when we try to create software to solve the real world problems we rarely use events. Instead we traditionally use abstract model to map out a logical path for what we observed in the domain, which often result in so-called God objects.
The advantages of using Events in the software are:
- they are immutable
- they ensure you never miss a thing
- and they can be replayed
CQRS vs Event Sourcing - transitioning from a system focused on models to persist, to a system focused on events to log.
Very often, software may not start out with a need to track history, but when the need arise, the data model design implemented only keeps track of the most current state of the system, and is unable to provide information on the historical state and specific points in time.
All applications, even common applications, need to use Events. The use-case just has not arise yet.
Event Sourcing Overview
Event Sourcing is about ensuring that all changes made to the application state during the entire lifetime of the application are stored as a sequence of events. The serialized events are actually the data source for the application. Key facts:
- an Event is something that has already happened in the past (events can be duplicated or replicated for scalability purpose).
- any behavior associated with the physical event has already been performed (it is not necessary to repeat the behavior when replaying an Event in the system).
- everything that happened is tracked at the time it happened as Events (regardless the effects produced, in other words the latest system state, since such information are indirectly stored in the lower abstraction level of Events).
- an Event is an expression of the ubiquitous language
- Events are not imperative and are named using past tense verbs (to indicate that things have occurred)
- have a persistent store for Events
- append-only, no deletion
- replay related Events to get the last known state of an entity, (instead of storing only the current state. to optimize performance, snapshot of states at a point in time can also be stored, so that replay only needs to start from snapshot.)
Transitioning to Event Sourcing
Two approach to get started transitioning a traditional data system:
- Continue to store current system state, but also start logging corresponding events that changed the state.
- Start storing events, and only build the latest system states from store of events.
We will also need to transition to a CQRS architecture as a Command stack is more ideal to act on Event stream and a Query stack is more optimized to display data. However, it is up to us to decide whether the Query stack data is updated first and propagated to Command stack, or vice versa.
Event-based Persistence
Event store are transparent to storage, meaning almost all storage technologies are able to serve the purpose (relational, NoSQL, Graph). Events should ideally store the following:
- Global event ID
- Type of operation
- Timestamp
- Entity identifier
- Transaction details / Changes applied / Reasons or Purpose
We may consider storing the most updated state of the entity alongside the Event when logging to the event store, which will optimize query performance.
We may implement undo feature for events by either physical deletion or logical deletion, but take note that there should be no deletion in the middle of a stream as this will result in corrupted and inconsistent system state.
Since events are constant data (because of immutability), event store can be easily replicated, increasing the potential to scale the application up.
Data Projections for Stored Events
Replay of events is a two step process that rebuilds the state of the system:
- first, grab all events in the event store for a certain aggregate using the desired entity ID.
- next, iterate through those selected events and apply all the information to a new instance of the aggregate.
Key functions that need to be in place:
- the event store has to allow querying of partial or full event stream (by aggregate ID and timestamp).
- events need to capture all key identifier and data
- code that return new instance of aggregates with updated state by parsing an event stream.
Snapshots can be created from events, which record the system state at a specific point in time, so that subsequent replay of events only need to start from the snapshot, improving replay processing speed.
Important Clarifications about Event Replay
- Replay is not about repeating the commands that generated the events. It is merely looking at events to extract information.
- Replay merely copies the effects that occurred in the system when the events were first triggered, and applying them to fresh aggregate instances.
- Replaying of the same event stream on different applications may require different processing logic.
- Replaying is the projection of data (events) stored in lower abstraction level. Getting the most current state of the system is merely one variant of data projection. Replay can be used for business intelligence, business analysis, simulations and etc.
Event Stores API
Event-based data store products typically provides API to interact with event streams. Streams equate to aggregates in the domain.
The API exposes the ability to write events to stream, read events from stream, and subscribing to stream for updates.
There are 3 types of subscriptions to stream:
- Volatile: call back to a function will be triggered whenever an event is written to a given stream, until the subscription is stopped.
- Catch-up: call back to a function from a given event in a given stream, right up to the end of the stream, and then turns to a Volatile subscription.
- Persistent: multiple consumers are guaranteed to receive at least one notification of events. Delivery of events may be duplicated or out of order, and it is up to the consumer implementation to be idempotent.
Volatile subscriptions are good for implementing Denomalizers in CQRS (which are responsible for projecting data to the Query stack).
Designing Software, Driven by Domain
Applying DDD to Legacy Code
- rewrite the system from scratch with only the abstractions you need.
- while rewriting, consider incorporating assets in the existing legacy system as services.
- Put legacy assets behind a facade and connect it to the core applications.
- Those that cannot be reused or exposed as a service, and if cost outweighs benefit, then perhaps we need a full rewrite.
UX-Driven Design
A UX-driven design generally follows these steps:
- Build up UI forms that users love (followed by agreement and sign off on the specifications before step 2).
- Define workflow from UI.
- COnnect workflows with existing business logic.
For each screen, have a basic flowchart:
- determine what comes in and out, and create view model classes.
- make application layer endpoints receive/return such DTO classes.
- make application layer orchestrate tasks on layers down the stack.
The UX Architect, who work alongside the software architect, defines the information architecture and content layout, defines the ideal interaction (storyboards for each screen and each UI trigger), defines the visual design, and conducts usability reviews.
Pillars of Modern Software
- Domain Analysis to address business needs.
- Layered architecture provides scalability.
- Top-down design approach, focused on tasks and on UX.
- CQRS powered by Events.